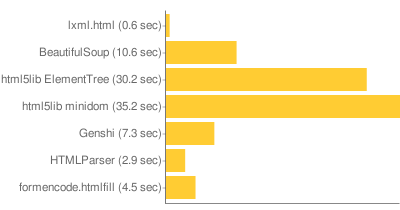
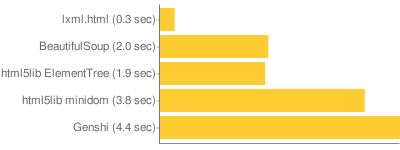
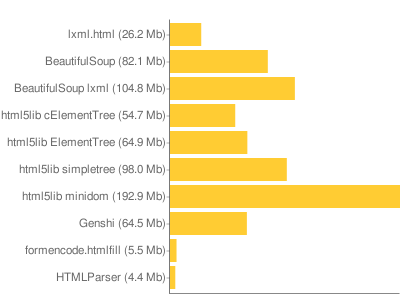
Environmental Guilt
I was offhandedly reading this post, which talked about Earth Hour, and about hating on SUVs:
Also thinking of a nice, simple mass-action for discouraging the SUV-ites. Simple, direct; when you see someone driving an SUV, slowly shake your head in disappointment and disgust at the stupidity of the driver. Throw in a disgusted sneer and snort if you like. It’s not necessarily the driver that you’re targeting, the people around you are probably more likely to affect purchasing decisions.
Well, a rather pedestrian level of hate as environmental discussions go.
I hate SUVs too. There’s a very small number of people who have good reason to own an SUV. Everyone else should own a normal car or a minivan (more practical in all the ways that matter, it just doesn’t look as cool). OK, the irony is that the minivan isn’t going to be much more efficient, it’s just that I’ll trust you have good reason to own a big vehicle, because you’ll have weighed the utility against the supreme uncoolness of a minivan. And anyway, four people barreling down the highway in a minivan is more efficient than one person in a Prius. With an SUV I’ll always suspect vanity. And what’s worse, I won’t think less of you just because of the resources you take up (not just carbon, but street space, visual, impact, etc)… I’ll also think less of you because I’ll have you pegged as a dumb consumer. And don’t give me any bullshit about getting around in the snow — then I’ll just peg you as a lousy driver, because I’ve been driving out of snow drifts in crappy low-clearance underpowered cars all my life without much trouble.
But I digress. Yeah, SUVs are shit. So what does it matter if I think so? I can only not buy an SUV so many times. If I don’t buy a million SUVs will I have saved the world? No. So, like Mike I wish I could get other people not to buy SUVs. I’ve considered tagging SUVs with these bumper stickers, but I dunno. Will I do anything more than piss some people off? If I make some soccer-mom type feel guilty, will I have actually accomplished anything? I think she’s a stupid consumer, and probably self-centered in her choice, but do I actually want that person to feel bad, or mad, or unjustly accused? The only outcome I can think of is some negative reaction, and maybe that reaction could be productive. But probably not.
The idea really fell apart as I reflected on all the Hispanic people in their SUVs going to the Catholic church next door, and realized that if I tagged one of their SUVs it would probably be even more pointless. This was their symbol of success, and you certainly can’t fault them for getting a big vehicle if they are filling it up, even if their particular choice of SUV was just a reflection of cowboy dreams — but when they bought the SUV instead of the minivan they only wasted some money, they didn’t really do any worse for the world.
But getting beyond the particulars of SUVs, I feel environmentalism has a real problem. It is built on guilt. A NIMBY action, or maybe land conservation, can actually be explained as rational direct action. Personal effort can result in the improvement of your personal space. But global warming? Personal action doesn’t do anything, it can’t do anything. All we have is guilt, a sense of collective responsibility, fear over some collective doom.
Guilt is a crappy foundation for a movement. One thing our commercial and consumerist world has going for it: there’s no guilt. The salesman won’t question why you are buying something. It’s always "thank you sir, have a nice day!" And even though sophisticated people will mock the insincerity of the expression, we’re still human and a kind word and a smile still makes us feel better, no matter how our rational mind rejects it.
But environmentalism? The most common reactions to guilt are avoidance, procrastination, resentment. Guilt is a horrible way to achieve action. Judgment can be a way to build group identity, and environmentalism has achieved this. It means something to be an "environmentalist". But that’s hardly the goal, is it?
People want to do the right thing for the world. They want to stop global warming, they want to reduce pollution, save wildlife, all that stuff. All the surveys show this. We’re not going to get any closer to consensus (on goals) than we are already. If we, collectively and individually, are still not doing what we need to, then it is not for lack of a collective desire, or even a lack of education.
So how do we turn desire into action? I don’t think guilt is a good way to do it. I’m not sure I like that path anyway. Is it an irrational reaction to guilt that we try to avoid judgment? Is it irrational that people are drawn to an environment where they are told they are good, where they are accepted, where they can act to achieve clear goals (even if that is just a purchase), where they can succeed? Consumerism may only draw people to an unimpressive local maximum of happiness, but it always makes the pursuit clear, consumerism draws you forward, consumerism offers a clear path.
And even if you choose to accept and respond to the guilt of environmentalism, it won’t stop. First you turn the water off while you are brushing your teeth. Then you get rid of the SUV. You replace your bulbs with CFLs. Are you ready to get rid of your drier? Put your thermostat at 60F? Eat organic? Stop eating meat? Join or start a co-op? Get a composting toilet? Go off the grid? There’s always more to be done, there’s always another thing to feel guilty about not doing. It’s disheartening.
Is there a way environmentalism can be less depressing? Less guilt-driven? Less accusing and judgmental? Can environmentalism be less dismal, more happy? Environmentalism is trying to drive a wedge between what people want and what they do. Putting aside moral arguments, is this an effective way to make change?
Considering my carbon footprint has only made this worse. Every action is negative. Everything I do has a cost. Pursuing carbon neutrality feels like a pursuit of non-existence. People are questioning the growth imperative, but at least growth has a certain excitement to it. Do we step into the future with confidence or fear? Do we take each step with trepidation and dread? What a horrible way to come into contact with our future selves! I want to meet all of our future selves with arms open. Buying shit is a poor substitute for that optimism. But dammit, I want to be optimistic. I don’t want to just be guilty.